The attitude towards research methodology in computer vision
cite from: http://www.stat.ucla.edu/~sczhu/research_blog.html
1, How to reach the moon?
2, Is vision a classification problem solvable by machine learning?
3, Hack, Math and Stat: why should we be tolerant of different styles in vision?
4, If you cannot solve a simple problem, you must solve a complex one !
1, How to reach the moon: do we know that we are not doing research in the wrong way? (2010)
Vision is arguably one of the most challenging, and potentially useful, problem in modern science and engineering for its enormous complexity in knowledge representation, learning and the computing mechanisms of the biologic systems. For such a complex problem, we must look for a long term solution, and be cautious that many apparently promising ways may lead to dead ends. By analogy, suppose some monkeys want to reach the moon, they may choose to (1) climb a tree, indeed, a tree could be so tall that a monkey climbs diligently for a life time, (2) grab the moon from a well at night time, or (3) ride a hot air balloon! All these methods appear to be smart and actually very cute, and people can enjoy measurable progress over time! while the real solution (building a spacecraft) looks hopeless for a long time and appears to be totally ridiculous to ordinary eyes ! In reality, most people simply do not have the patience to learn astrophysics and rocket science, which are too complex and boring for them.
———————————— Comic illustrated by my daughter Stephanie Zhu (11 yrs old drawn in 2010): How to reach the moon.

2, Is vision a classification problem solvable by machine learning? (2011)
Some students asked me whether vision is just an application area of machine learning (which currently means training Boosting or SVM classifiers with large number of examples) as it appears to them. If so, what left for vision researchers is just to design good features. Such question is a real insult to vision and reflects the misleading research trend that poses vision as simple as a classification problem. This is no longer surprising to me, as the young generation not only never heard of Ulf Grenander (the father of pattern theory), but now didn’t know who David Marr (father of computational vision) was. By analogy, machine learning, with its popular meaning, is very much like the method practiced by Chinese herbal clinics over the past three thousand years. Ancient people, who had little knowledge of modern medicine, tried on 100s of materials (roots, seeds, shells, worms, insects, etc) just like machine learning people test on various features. These ingredients are mixed with weights and boiled to black and bitter soup as drugs — a regression process. It is believed that such soup can cure all illness including cancer, SARS and HmNn flu, without having to understand either the biologic functions and causes of the illnesses or the mechanism of the drugs. All you need is to find the right ingredients and mix them in the right proportion (weights). In theory, actually you can prove that this is true (essentially, modern medicine mixes some sort of ingredients as well), just like machine learning methods are guaranteed to solve all problems if they have enough features and examples, according to statistics theory! But the question is: with the space of ingredients so large, how do we find the right ingredients effectively (with realistic number of examples for training as well as number of patients for testing)? For vision, we got to study the complex structures of the images, the rich spaces and their compositions, and the variety of models and representations.
————————————— Comic: the analogy between Chinese herbal clinic and machine learning (by a painter Kun Deng and me drawn in 2008).

3, Hack, Math and Stat: why should we be tolerant of different styles in vision. (2011)
Research methodologies in vision (and other sciences and engineering) can be summarized in three approaches or stages: Hack, Math, and Stat. Hacks are heuristics or somethings that somehow work somewhere, but you cannot tell exactly how and where they work. Math is on the opposite side, it tells us that under certain conditions, things can be said analytically or with a gaurantee of performance, but often the conditions are quite limited and do not apply to general situations in the real world. Stat is essentially regression. With lots of parameters, you eventually can fit any data, but lack a physical explanation. Hack, math, and stat are therefore different levels of interpretations or models. It is interesting to see examples in discplines that has a longer history, say physics. The Chinese expedition [1405-1433] in the Ming dynasty was the most advanced of its time when folks sailed 2/3 of the world reaching Africa and Europe without even knowing the Earth is round ! The technique they used is called celestial navigation (see the picture below), which I call “hacks” here. People used the constalletions to find the north and the latitude. the constellations are very much like shape features we are using today for object recognition. It was not precise, but worked to some extent in practice. A beautiful math theory appeared in the 1680s* when Newton invented the gravitation theory which is simple and explains the movements of stars and planets. But the math is not suffisticated enough to explain fully the motion of moon. Newton was reported said that the lunar theory “made his head ache and kept him awake so often that he would think of it no more”**. In 1750s, it was the French talents like Euler and a few others who came to rescue. They invented the least-sqaured method to fit the observational data perfectly with regression (see the equation below). Such regression equations looks very familiar in machine learning today. Hack, math, and stat are all useful tools and methods, and often a complex solution integrates all three of them. For example, in image compression and coding, we have the math in information theory, wavelets and computational mononic analysis at its core. Then we also use statistics for the frequency of various elements in the code book. Finally the coding scheme contains numerous engineering hacks to make it work in real images/video, such as jpg and mpeg. It is likely the solution to vision will rely on all three aspects, and you need to be good at all three aspects if you are serious at solving the vision problems.

————————————————————————————— From a talk I gave at the Frontiers of Vision at Boston in 2011. Download the whole ppt.
4, If you cannot solve a simple problem, then you must solve a complex one! (2014)
Reductionism is a beloved research strategy in many areas of modern science. It says that if you cannot solve a problem, you should divide it into smaller components as any complex system is nothing but the sum of its parts. This methodology was practiced by early vision researchers in the 1980s, for example, numerous methods for edge detection, segmentation, shape-from-X etc. But, people found that even the simplest problem like edge detection couldn’t be solved, because the definition of an edge depends on tasks in higher levels and even human labelers cannot agree whether there is an edge without specifying the task levels. Unlike physicists who can choose to study a system or phenomenon at a given scale or status, computer vision researchers found themselves very unfortunate: each single image contains so many patterns and tasks across many levels! The table below lists a set of questions that we must solve, all together, in order to understand a single image. So, we go the opposite direction: if you cannot solve a simple problem, you must solve a complex one! This motivated our work for developing a unified representation — spatial, temporal and causal and-or graph and making joint parsing of all the tasks on the table (see our demo page ). Now it reminds me of a loud slogan in machine learning: You should never solve a problem more than necessary (by Vapnik). This was used to argue for discriminative models against generative models. The slogan itself has nothing wrong, but unfortunately we just don’t have such well-defined problems to solve in computer vision! Edge detection was thought to be a classification problem, but it is not. I am also reminded that physicists are taking our approach lately. For example, the concept of Dark Matter/Energy is to construct a more complex system than what we can see, and in superstring theory, people go to 10 dimensional space in order to put relativity theory and quantum mechanics in peace.
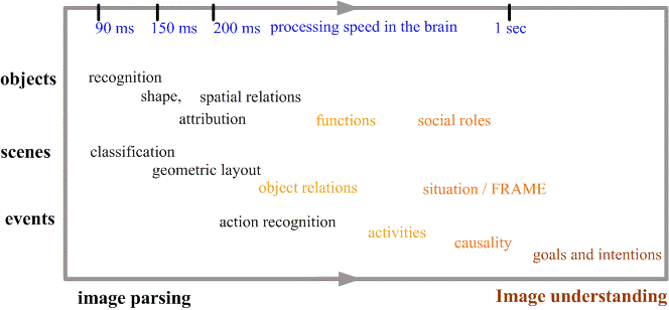
————————————————————— This table lists the aspects for scene understanding that we promised in 2010 to study in the ONR MURI project.
Great!